|
|
@@ -0,0 +1,319 @@
|
|
|
+# 第6章 支持向量机
|
|
|
+## 6.1 间隔与支持向量
|
|
|
+超平面的方程可以表示为:
|
|
|
+$$\tag{6.1} w^Tx+b =0$$
|
|
|
+
|
|
|
+**推导6.1**
|
|
|
+
|
|
|
+样本数据集:
|
|
|
+$$\begin{pmatrix}
|
|
|
+ x_1^0,x_2^0,x_3^0,\dots,x_m^0 \\
|
|
|
+ x_1^1,x_2^1,x_3^1,\dots,x_m^1 \\
|
|
|
+ x_1^2,x_2^2,x_3^2,\dots,x_m^2\\
|
|
|
+ x_1^3,x_2^3,x_3^3,\dots,x_m^3\\
|
|
|
+ \dots\\
|
|
|
+ x_1^n,x_2^n,x_3^n,\dots,x_m^n
|
|
|
+ \end{pmatrix}其中x_n^m表示第m个样本的第n个特征,这里对每一个样本添加一个x_0 = 1
|
|
|
+$$
|
|
|
+$$\begin{pmatrix}
|
|
|
+ y_1,
|
|
|
+ y_2,
|
|
|
+ y_3,
|
|
|
+ \dots,
|
|
|
+ y_m
|
|
|
+ \end{pmatrix}其中y_m表示第m个样本的lable$$
|
|
|
+ $$w^T = \begin{pmatrix}
|
|
|
+w_0,w_1 , w_2, w_3, \dots, w_n
|
|
|
+ \end{pmatrix},其中w为超平面的法向量,决定了超平面的方向,w_0 * x_0 = b 为位移项,决定了超平面与原点之间的距离$$
|
|
|
+
|
|
|
+**(6.2)**
|
|
|
+下面我们将超平面的方程标记为$(w,b)$,**样本空间中任意点$x$到超平面$(w,b)$的距离**可写为
|
|
|
+$$\tag{6.2} r = \frac{|w^Tx+b|}{||w||}$$
|
|
|
+**推导(6.2)**
|
|
|
+在二维平面d怎么求?(点到直线的距离公式)
|
|
|
+$(x,y)$到$Ax+By+C=0$的距离用以下公式表示
|
|
|
+$$d=\frac{|Ax+By+C|}{\sqrt{A^2+B^2}}$$
|
|
|
+ 拓展到n维空间有:$w^Tx_b=0$→$w^Tx+b=0$
|
|
|
+$$||w|| = \sqrt{w_1^2+w_2^2 +\cdots + w_n^2}$$
|
|
|
+
|
|
|
+
|
|
|
+假设超平面$(w,b)$能够将训练样本正确分类,即对于$(x_i,y_i)\in D$,若$y_i = +1$,则有$w^Tx_i + b \gt0$;若$y_i = -1$,则有$w^Tx_i + b \lt0$。
|
|
|
+$$\tag{6.3} \begin{cases}
|
|
|
+ w^Tx_i+b \geqslant + 1 &\text{ } y_i = +1 \\
|
|
|
+ w^Tx_i+b \leqslant - 1 &\text{ } y_i = -1
|
|
|
+\end{cases}$$
|
|
|
+**推导6.3**
|
|
|
+$空间任意一点到超平面的距离为d$
|
|
|
+
|
|
|
+$$d=\frac{|w^Tx+b|}{||w||}$$
|
|
|
+$$||w|| = \sqrt{w_1^2+w_2^2 +\cdots + w_n^2}$$
|
|
|
+
|
|
|
+$$\begin{cases}
|
|
|
+ \frac{w^Tx_i+b }{||w||}\geqslant d & \forall y_i=1 \\
|
|
|
+ \frac{w^Tx_i+b}{||w||}\leqslant -d & \forall y_i=-1 \\
|
|
|
+\end{cases}
|
|
|
+\implies \begin{cases}
|
|
|
+ w_d^T x_i + b_d\geqslant 1 & \forall y_i=1 \\
|
|
|
+ w_d^T x_i+ b_d \leqslant -1 & \forall y_i=-1 \\
|
|
|
+\end{cases}$$
|
|
|
+其中$$\begin{cases}
|
|
|
+ w_d^T = \frac{w^T}{d}\\
|
|
|
+ b_d = \frac{b}{d} \\
|
|
|
+\end{cases}$$
|
|
|
+对于决策边界的超平面方程:$w_d^Tx+b_d=0$
|
|
|
+**重命名!!! 令**$$\begin{cases}
|
|
|
+ w_d^T = w^T\\
|
|
|
+ b_d = b \\
|
|
|
+\end{cases}\implies w^Tx+b=0\implies \begin{cases}
|
|
|
+ w^T x_i + b\geqslant 1 & \forall y_i=1 \\
|
|
|
+ w^T x_i+ b \leqslant -1 & \forall y_i=-1 \\
|
|
|
+\end{cases}$$
|
|
|
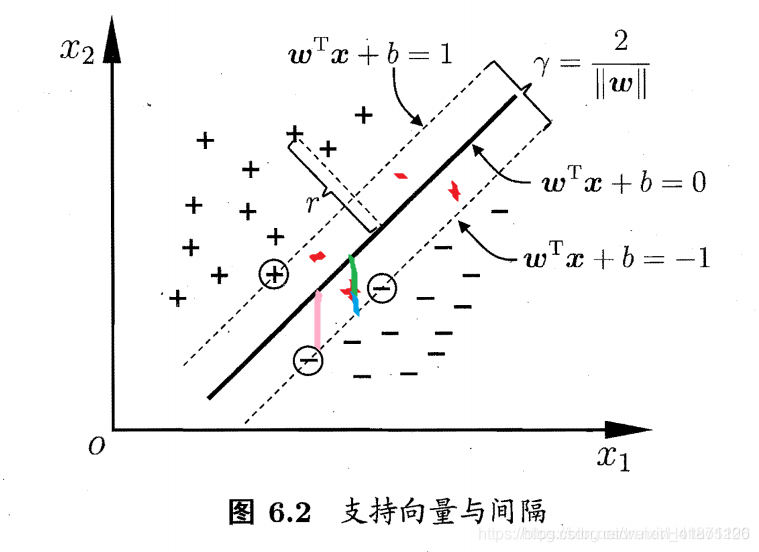
+距离超平面最近的这几个训练样本点使式 (6.3) 的等号成立,它们被称为"支持向量" (surport vector),两个异类支持向量到超平面的距离之和为:
|
|
|
+$$\tag{6.4} \gamma =\frac{2}{||w||}$$
|
|
|
+**推导6.4**
|
|
|
+在超平面的一边的同类支持向量构成决策边界方程为:
|
|
|
+$$ w^T x_i + b = 1$$
|
|
|
+超平面到该决策边界的距离为:
|
|
|
+$$\gamma = \frac{1}{||w||}$$
|
|
|
+[两平行直线之间的距离](https://www.zybang.com/question/9ae10a9debbc467c22d61ce2f1d87178.html)
|
|
|
+
|
|
|
+
|
|
|
+欲找到具有"最大间隔" (maximum margin) 的划分超平面,也就是要找
|
|
|
+到能满足式 (6.3) 中约束的参数$w$和$b$,使得$\gamma$最大,即
|
|
|
+$$\tag{6.5} \underbrace{max}_{\text{$w,b$}}\frac{2}{||w||} $$
|
|
|
+
|
|
|
+$$s.t.\quad y_i(w^Tx_i+b) \geqslant 1,\quad i=1,2 \dots m$$
|
|
|
+显然为了最大化间隔$\gamma$,仅需最大化$\frac{2}{||w||}$ ,这等价于最小化$||w||$ **(加上系数与平方,只是为了计算方便)**。
|
|
|
+$$\tag{6.6} \underbrace{min}_{\text{$w,b$}}\frac{1}{2} ||w||^2$$
|
|
|
+
|
|
|
+$$s.t.\quad y_i(w^Tx_i+b) \geqslant 1,\quad i=1,2 \dots m$$
|
|
|
+
|
|
|
+## 6.2 对偶问题
|
|
|
+求解式 (6.6)来得到大间隔划分超平面所对应的模型
|
|
|
+$$\tag{6.7} f(x) = w^Tx+b$$
|
|
|
+对式 (6.6)使用拉格朗日乘子法可得到其"对偶问题" (dual problem). 具体来说,对式 (6.6) 的每条约束添加拉格朗日乘子$\alpha \geqslant 0$,则该问题的拉格朗日函数可写为:
|
|
|
+$$\tag{6.8} L(w,b,\alpha) = \frac{1}{2}||w||^2+\sum_{i=1}^m\alpha_i(1-y_i(w^Tx_i+b))$$
|
|
|
+**推导6.8**
|
|
|
+$其中\alpha = (\alpha_1;\alpha_2;\cdots\alpha_m).令L(w,b,\alpha)对w和b的偏导为0$
|
|
|
+$$\begin{aligned}L(w,b,\alpha) &= \frac{1}{2}||w||^2+\sum_{i=1}^m\alpha_i(1-y_i(w^Tx_i+b))
|
|
|
+\\
|
|
|
+& = \frac{1}{2}||w||^2+\sum_{i=1}^m(\alpha_i-\alpha_iy_iw^Tx_i+\alpha_iy_ib)\\
|
|
|
+& =\frac{1}{2}||w||^2+\sum_{i=1}^m\alpha_i -\sum_{i=1}^m\alpha_iy_iw^Tx_i +\sum_{i=1}^m\alpha_iy_ib
|
|
|
+\end{aligned}$$
|
|
|
+$(1)对w和b分别求偏导数$
|
|
|
+
|
|
|
+$$\frac {\partial L}{\partial w}=w - \sum_{i=1}^{m}\alpha^iy^ix^i = 0 \implies w=\sum_{i=1}^{m}\alpha^iy^ix^i$$
|
|
|
+
|
|
|
+$$\frac {\partial L}{\partial b}=\sum_{i=1}^{m}\alpha^iy^i0 \implies \sum_{i=1}^{m}\alpha^iy^i = 0$$
|
|
|
+$$\tag{6.9} w = \sum_{i=1}^m\alpha_iy_ix_i $$
|
|
|
+
|
|
|
+$$\tag{6.10} 0=\sum_{i=1}^m\alpha_iy_i$$
|
|
|
+
|
|
|
+$$\tag{6.11} L(w,b,\alpha) =\underbrace{max}_{\text{$\alpha$}}\sum_{i=1}^m\alpha_i - \frac{1}{2}\sum_{i = 1}^m\sum_{j=1}^m\alpha_i \alpha_j y_iy_jx_i^Tx_j$$
|
|
|
+**推导6.11**
|
|
|
+将式 (6.9)代人 (6.8) ,即可将$L(w ,b ,\alpha)$ 中的 $w$ 和 $b$ 消去,再考虑式 (6.10) 的约束,就得到式 (6.6) 的对偶问题
|
|
|
+$$\begin{aligned}
|
|
|
+ L(w,b,\alpha) &=\frac {1}{2}w^Tw+\sum _{i=1}^m\alpha_i[1-y_i(w^Tx_i+b)]\\ & =\frac {1}{2}w^Tw+\sum _{i=1}^m\alpha_i - \sum _{i=1}^m\alpha_iy_iw^Tx_i-\sum _{i=1}^m\alpha_iy_ib\\
|
|
|
+&=\frac {1}{2}w^T\sum _{i=1}^m\alpha_iy_ix_i-w^T\sum _{i=1}^m\alpha_iy_ix_i+\sum _{i=1}^m\alpha_
|
|
|
+i -\sum _{i=1}^m\alpha_iy_ib\\
|
|
|
+& = -\frac {1}{2}w^T\sum _{i=1}^m\alpha_iy_ix_i+\sum _{i=1}^m\alpha_i -\sum _{i=1}^m\alpha_iy_ib\\
|
|
|
+&=-\frac {1}{2}w^T\sum _{i=1}^m\alpha_iy_ix_i+\sum _{i=1}^m\alpha_i -b\sum _{i=1}^m\alpha_iy_i\\
|
|
|
+&=-\frac {1}{2}(\sum_{i=1}^{m}\alpha_iy_ix_i)^T(\sum _{i=1}^m\alpha_iy_ix_i)+\sum _{i=1}^m\alpha_i -b\sum _{i=1}^m\alpha_iy_i\\
|
|
|
+&=-\frac {1}{2}\sum_{i=1}^{m}\alpha_iy_i(x_i)^T\sum _{i=1}^m\alpha_iy_ix_i+\sum _{i=1}^m\alpha_i -b\sum _{i=1}^m\alpha_iy_i\implies其中 \sum_{i=1}^{m}\alpha_iy_i = 0\\
|
|
|
+&= -\frac {1}{2}\sum_{i=1}^{m}\alpha_iy_i(x_i)^T\sum _{i=1}^m\alpha_iy_ix_i+\sum _{i=1}^m\alpha_i \\
|
|
|
+&=\sum _{i=1}^m\alpha_i-\frac {1}{2}\sum_{i=1 }^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_j(x_i)^Tx_j
|
|
|
+\end{aligned}$$
|
|
|
+
|
|
|
+$$s.t. \quad \sum_{i=1}^m \alpha_i y_i = 0,$$
|
|
|
+
|
|
|
+$$\alpha _i \geqslant 0,\quad i=1,2\dots,m$$
|
|
|
+
|
|
|
+将(6.9)带入$f(x)$得:
|
|
|
+$$\tag{6.12} f(x) = w^Tx+b = \sum_{i=1}^{m}\alpha_iy_ix_i^Tx+b$$
|
|
|
+从对偶问题 (6.11)解出的$\alpha_i$是式 (6.8) 中的拉格朗日乘子,它恰对应着训练样本 $(x_i ,y_i)$. 注意到式 (6.6) 中有不等式约束,因此上述过程需满足KKT(Karush-Kuhn-Tucker) 条件,即要求:
|
|
|
+$$\tag{6.13} \begin{cases}
|
|
|
+ \alpha_i \geqslant 0; &\text{ } \\
|
|
|
+ y_if(x_i)-1 \geqslant0;&\text{}\\
|
|
|
+ \alpha_i(y_if(x_i) -1) =0
|
|
|
+\end{cases}$$
|
|
|
+$使用SMO算法,固定\alpha_i,\alpha_j以外的参数,则有:$
|
|
|
+$$\tag{6.14} \alpha_iy_i + \alpha_jy_j = c,\quad \alpha_i \geqslant 0 ,\quad \alpha_j\geqslant0$$
|
|
|
+$$\tag{6.15}c = -\sum_{k\ne i,j}\alpha_ky_k$$
|
|
|
+$$\tag{6.16}\alpha_iy_i+\alpha_jy_j = c$$
|
|
|
+对于任何支持向量都有
|
|
|
+$$\begin{cases}
|
|
|
+ w^T x_s + b=1 & \forall y_s=1 \\
|
|
|
+ w^T x_s+ b= -1 & \forall y_s=-1
|
|
|
+\end{cases} \implies y_sf(x_s)= 1$$
|
|
|
+$$\tag{6.17}y_s(\sum_{i\in S}\alpha_iy_ix_i^Tx_s+b) = 1$$
|
|
|
+**推导6.17**
|
|
|
+(6.17)等式两边同乘$y_s$
|
|
|
+$$y_s^2(\sum_{i\in S}\alpha_iy_ix_i^Tx_s+b) = y_s,\quad其中y_s^2 =1$$
|
|
|
+
|
|
|
+$$\tag{6.18}b = \frac{1}{|S|}\sum_{s\in S}(y_s - \sum_{s\in S}\alpha _iy_ix_i^Tx_s)$$
|
|
|
+## 6.3 核函数
|
|
|
+
|
|
|
+$\text{\o}(x)表示将 x映射
|
|
|
+到一个合适的高维空间 后的特征向量$
|
|
|
+$$\tag{6.19}f(x) = w^T\text{\o}(x) +b$$
|
|
|
+$$\tag{6.20} \underbrace{min}_{\text{$w,b$}}\frac{1}{2}||w||^2$$
|
|
|
+
|
|
|
+$$s.t. \quad y_i(w^T\text{\o}(x_i)+ b)\geqslant 1,\quad i = 1,2\dots m$$
|
|
|
+
|
|
|
+$$\tag{6.21}\underbrace{max}_{\text{$\alpha$}}\sum_{i=1}^m\alpha_i - \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j\text{\o}(x_i)^T(x_j)$$
|
|
|
+
|
|
|
+$$s.t. \quad \sum_{i=1}^m\alpha_iy_i = 0$$
|
|
|
+$$\alpha_i\geqslant0,\quad i =1,2,\dots,m$$
|
|
|
+[半正定矩阵和正定矩阵](https://blog.csdn.net/asd136912/article/details/79146151)
|
|
|
+$$\tag{6.22}\kappa(x_i,x_j) =\lang\text{\o}(x_i),\text{\o}(x_j)
|
|
|
+\rang = \text{\o}(x_i)^T\text{\o}(x_j)$$
|
|
|
+$$\tag{6.23} \underbrace{max}_{\text{$\alpha$}} \sum_{i=1}^m\alpha_i - \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_j\kappa(x_i,x_j) $$
|
|
|
+
|
|
|
+$$s.t. \quad \sum_{i=1}^m\alpha_iy_i =0$$
|
|
|
+
|
|
|
+$$\alpha_i \geqslant 0,\quad i =1,2\cdots,m$$
|
|
|
+$$\tag{6.24}\begin{aligned} f(x) &=w^T\text{\o}(x) +b \\&=\sum_{i=1}^m\alpha_iy_i\text{\o}(x_i)^T\text{\o}(x) +b
|
|
|
+\\&=\sum_{i=1}^m\alpha_iy_i\kappa(x_i,x_j) +b\end{aligned}$$
|
|
|
+为核函数还可通过函数组合得到,例如:
|
|
|
+* 若$\kappa_1和\kappa_2$为核函数,则对于任意正数$\gamma_1,\gamma_2$,其线性组合
|
|
|
+$$\tag{6.25}\gamma_1\kappa_1+\gamma_2\kappa_2$$
|
|
|
+* 若$\kappa_1和\kappa_2$为核函数,则核函 数的直积
|
|
|
+$$\tag{6.26}\kappa_1\bigotimes\kappa_2(x,z) = \kappa_1(x,z)\kappa_2(x,z)$$
|
|
|
+* 若$\kappa_1$为核函 数,则对于任意函数$g(x)$,
|
|
|
+$$\tag{6.27} \kappa(x,z)=g(x)\kappa_1(x,z)g(z)$$
|
|
|
+
|
|
|
+## 6.4 软间隔与正则化
|
|
|
+
|
|
|
+
|
|
|
+$$\tag{6.28} \quad y_i(w^Tx_i+b) \geqslant 1,\quad i=1,2 \dots m$$
|
|
|
+$$\tag{6.29} \underbrace{min}_{\text{$w,b$}}\frac{1}{2} ||w||^2+C\sum_{i=1}^{m}l_{0/1}(y_i(w^Tx_i+b)-1)$$
|
|
|
+$$\tag{6.30}l_{0/1}(z)=\begin{cases}\\
|
|
|
+1 , z<0 \\
|
|
|
+0 ,otherwise\\
|
|
|
+\end{cases}$$
|
|
|
+在6.6式的基础上,我们把 不满足约束的样本以$l_{0/1}$损失函数引入进来 ,以实现允许少量样本不满足约束
|
|
|
+$$\tag{6.31}hingle损失:l_{hinge}=max(0,1-z);$$
|
|
|
+$$\tag{6.32}指数损失(exponential loss):l_{exp}(z)=exp(-z)$$
|
|
|
+$$\tag{6.33}对率损失(logistics loss):L_{log}(z)=log(1+exp(-z))$$
|
|
|
+ 我们用hinge损失代替$l_{0/1}$ $$\tag{6.29} \underbrace{min}_{\text{$w,b$}}\frac{1}{2} ||w||^2+C\sum_{i=1}^{m}max(0,1-y_i(w^Tx_i+b))$$
|
|
|
+
|
|
|
+引入“松弛变量”$\varepsilon_i$,为了方便理解,我们用‘红色’标出四个位于间隔内的点,粉色线段长度代表函数间隔(在这里为1)蓝色线段为$\varepsilon$ 绿色线段为$1-\varepsilon$ ,此时我们将(6.34)重写为$$$\tag{6.35} \underbrace{min}_{\text{$w,b,\varepsilon_i$}}\frac{1}{2} ||w||^2+C\sum_{i=1}^{m}\varepsilon_i$$ $$s.t.\quad y_i(w^Tx_i+b) \geqslant 1-\varepsilon_i,\quad i=1,2 \dots m$$ $$\varepsilon_i \geqslant 0 \quad i= 1,2,...m.$$
|
|
|
+
|
|
|
+$$\tag{6.36} L(w,b,\alpha,\varepsilon ,\mu) = \frac{1}{2}||w||^2+C\sum_{i=1}^m \varepsilon_i\\+\sum_{i=1}^m \alpha_i(1-\varepsilon_i-y_i(w^Tx_i+b))-\sum_{i=1}^m\mu_i \varepsilon_i$$在这部分由于存在两个月叔条件,我们引入两个拉格朗日乘子$\alpha ,\varepsilon$
|
|
|
+ 分别对$w,b,\varepsilon$求导并使其为0
|
|
|
+ $$\tag{6.37} \frac {\partial L}{\partial w}=w - \sum_{i=1}^{m}\alpha^iy^ix^i = 0 \implies w=\sum_{i=1}^{m}\alpha^iy^ix^i$$
|
|
|
+
|
|
|
+$$\tag{6.38} \frac {\partial L}{\partial b}=\sum_{i=1}^{m}\alpha^iy^i=0 \implies \sum_{i=1}^{m}\alpha^iy^i = 0$$
|
|
|
+
|
|
|
+$$\tag{6.39} \frac{\partial L}{\partial \varepsilon}=C\sum_{i=1}^m1-\sum_{i=1}^m \alpha_1 -\sum_{i=1}^m \,u_i \implies C=\alpha_i +\mu_i$$
|
|
|
+
|
|
|
+将式6.37-6.39代入6.36可以得到6.35的对偶问题——线性规划中普遍存在配对现象,每一个线性规划问题都存在另一个与他有对应关系的线性规划问题,其一叫原问题,其二叫对偶问题
|
|
|
+$$\begin{aligned}
|
|
|
+ L(w,b,\alpha,\varepsilon ,\mu) &= \frac{1}{2}||w||^2+C\sum_{i=1}^m \varepsilon_i+\sum_{i=1}^m \alpha_i(1-\varepsilon_i-y_i(w^Tx_i+b))-\sum_{i=1}^m\mu_i \varepsilon_i \\
|
|
|
+&=\frac{1}{2}||w||^2+\sum_{i=1}^m\alpha_i(1-y_i(w^Tx_i+b))+C\sum_{i=1}^m \varepsilon_i-\sum_{i=1}^m \alpha_i \varepsilon_i-\sum_{i=1}^m\mu_i \varepsilon_i \\
|
|
|
+& = -\frac {1}{2}\sum_{i=1}^{m}\alpha_iy_i(x_i)^T\sum _{i=1}^m\alpha_iy_ix_i+\sum _{i=1}^m\alpha_i +\sum_{i=1}^m C\varepsilon_i-\sum_{i=1}^m \alpha_i \varepsilon_i-\sum_{i=1}^m\mu_i \varepsilon_i \\
|
|
|
+& = -\frac {1}{2}\sum_{i=1}^{m}\alpha_iy_i(x_i)^T\sum _{i=1}^m\alpha_iy_ix_i+\sum _{i=1}^m\alpha_i +\sum_{i=1}^m (C-\alpha_i-\mu_i)\varepsilon_i \\
|
|
|
+&=\sum _{i=1}^m\alpha_i-\frac {1}{2}\sum_{i=1 }^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_j(x_i)^Tx_j \\
|
|
|
+&\tag{6.40}\underbrace{max}_{\alpha}\sum _{i=1}^m\alpha_i-\frac {1}{2}\sum_{i=1 }^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_j(x_i)^Tx_j \\
|
|
|
+ &s.t. \sum_{i=1}^m \alpha_i y_i=0 \\ & 0 \leq\alpha_i \leq C \quad i=1,2,\dots ,m
|
|
|
+\end{aligned}$$
|
|
|
+
|
|
|
+KKT条件,这里简单提一下不等式约束的KKT拉格朗日乘子为$\alpha$不等式约束为$\varepsilon$那么要满足$$\begin{cases}
|
|
|
+\alpha \geq0 \\
|
|
|
+\varepsilon \\
|
|
|
+\alpha \varepsilon=0
|
|
|
+\end{cases}$$
|
|
|
+$$\tag{6.41}\begin{cases}
|
|
|
+\alpha_i \geq0, \mu_i \geq0 ,\\
|
|
|
+y_if(x_i)-1+\varepsilon_i \geq0,\\
|
|
|
+\alpha_i(y_if(x_i)-1+\varepsilon_i)=0,\\
|
|
|
+\varepsilon_i \geq0, \mu_i \varepsilon_i=0.
|
|
|
+\end{cases}$$
|
|
|
+
|
|
|
+我们对不同的损失函数概括抽象推广到一般形式:
|
|
|
+$$\tag{6.42} \underbrace{min}_{f} \Omega(f)+C\sum_{i=1}^ml(f(x_i),y_i)$$
|
|
|
+
|
|
|
+
|
|
|
+## 6.5 支持向量回归
|
|
|
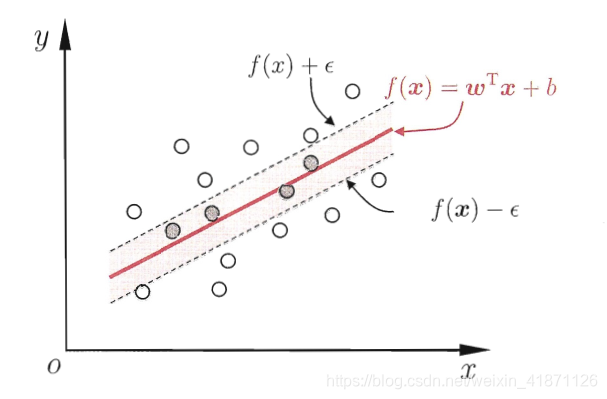
+在这里简单说一点,我们如何来看待分类和回归,分类的损失函数要么是1,要么是0,回归得的损失函数是连续的数值。支持向量回归我们容忍$f(x)$与y之间有$\epsilon$的误差,(结合图片,把6.43,6.44一起理解)
|
|
|
+$$\tag{6.43} \underbrace{min}_{\text{$w,b,\varepsilon_i$}}\frac{1}{2} ||w||^2+C\sum_{i=1}^{m}l_{\epsilon}(f(x_i)-y_i) $$ $$ \tag{6.44}l_{\epsilon}(z)= \begin{cases}\\ 0, if|z| \leq \epsilon \\|z|-\epsilon,otherwise \end{cases}$$
|
|
|
+
|
|
|
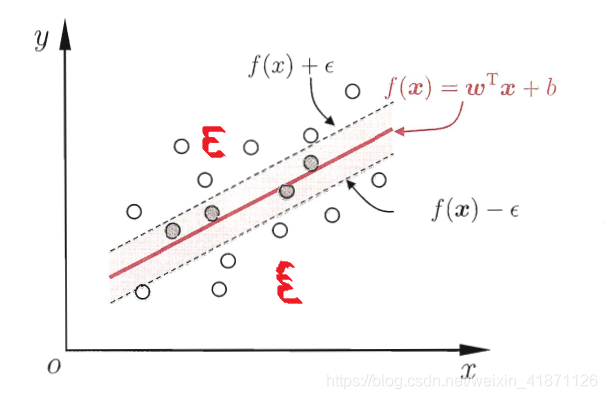
+如图所示我们在间隔两侧引入松弛变量$\varepsilon ,\hat\varepsilon$,就是在间隔$\epsilon$基础上我们重新增加了一部分“容忍量”
|
|
|
+$$\tag{6.45} \underbrace{min}_{\text{$w,b,\varepsilon_i,\hat \varepsilon_i$}}\frac{1}{2} ||w||^2+C\sum_{i=1}^{m}(\epsilon_i,\hat \varepsilon_i $$ $$f(x_i)-y_i\leq\epsilon+\varepsilon_i,$$ $$y_i-f(x_i) \leq\epsilon+\hat\varepsilon_i,$$ $$\varepsilon_i \geq0,\hat\varepsilon0,\quad i=1,2,\dots,m.$$
|
|
|
+
|
|
|
+引入拉格朗日乘子$\mu_i \geq0,m\hat\mu_i\geq0,对应两个松弛变量,\alpha-i\geq0,\hat\alpha_i\geq0对应两个约束条件$.
|
|
|
+$$\tag{6.46} L(w,b,\alpha,\hat\alpha,\varepsilon,\hat\varepsilon ,\mu,\hat\mu) = \frac{1}{2}||w||^2+C\sum_{i=1}^m (\varepsilon_i+\hat\varepsilon_i)-\sum_{i=1}^m\mu_i \varepsilon_i-\sum_{i=1}^m\hat\mu_i \hat\varepsilon_i\\+\sum_{i=1}^m \alpha_i(f(x_i)-y_i-\epsilon-\varepsilon_i)+\sum_{i=1}^m\hat\alpha_i(y_i-f(x_i)-\epsilon-\hat\varepsilon_i$$
|
|
|
+
|
|
|
+$ L(w,b,\alpha,\hat\alpha,\varepsilon,\hat\varepsilon ,\mu,\hat\mu)$分别对 $w,b,\varepsilon,\hat\varepsilon$求偏导并使其为0
|
|
|
+$$\tag{6.47} \frac{\partial L}{\partial w}=w-\sum_{i=1}^m\alpha_ix_i-\sum_{i=1}^m\hat\alpha_ix_i=0 \implies w=\sum_{i=1}^m(\hat\alpha_i-\alpha_i)x_i $$ $$\tag{6.48} \frac{\partial L}{\partial b}=\sum_{i=1}^m\alpha_i -\sum_{i=1}^m\hat\alpha_i=0 \implies 0=\sum_{i=1}^m(\hat\alpha_i-\alpha_i)$$ $$\tag{6.49} \frac{\partial L}{\partial \varepsilon_i}=C\sum_{i=1}^m1-\sum_{i=1}^m \alpha_1 -\sum_{i=1}^m \,u_i \implies C=\alpha_i +\mu_i$$ $$\tag{6.50} \frac{\partial L}{\partial \hat\varepsilon_i}=C\sum_{i=1}^m1-\sum_{i=1}^m \hat\alpha_1 -\sum_{i=1}^m \hat\mu_i \implies C=\hat\alpha_i +\hat\mu_i$$
|
|
|
+
|
|
|
+将6.47-6.50代入6.46,即可得到SVR的对偶问题
|
|
|
+$$\begin{aligned}
|
|
|
+L(w,b,\alpha,\hat\alpha,\varepsilon,\hat\varepsilon ,\mu,\hat\mu) =-\frac{1}{2}w^T\sum_{i=1}^m(\hat\alpha_i-\alpha_i)x_i+\sum_{i=1}^m(\alpha_i\varepsilon_i+\alpha_i\hat\varepsilon_i+\mu_i\varepsilon_i+\mu_i\hat\varepsilon_i-\mu_i\varepsilon_i-\hat\mu_i\hat\varepsilon_i)\\
|
|
|
++\sum_{i=1}^m\alpha_i((w^Tx_i+b)-y_i-\epsilon-\varepsilon_i)+\sum_{i=1}^m\hat\alpha_i(y_i-(w^T+b)-\epsilon-\hat\varepsilon_i)\\
|
|
|
+=\sum_{i=1}^m(\alpha_i\varepsilon_i+\alpha_i\hat\varepsilon_i+\mu_i\varepsilon_i+\mu_i\hat\varepsilon_i-\mu_i\varepsilon_i-\hat\mu_i\hat\varepsilon_i-\mu_i\varepsilon_i-\hat\mu_i\hat\varepsilon_i-\alpha_i\varepsilon_i-\hat\alpha_i\hat\varepsilon_i)\\
|
|
|
++\sum_{i=1}^m[y_i(\hat\alpha_i-\alpha_i)-\epsilon(\hat\alpha_i+\alpha_i)]-\frac{1}{2}w^T\sum_{i=1}^m(\hat\alpha_i-\alpha_i)x_i+\sum_{i=1}^m(\alpha_i-\hat\alpha_i)w^Tx_i\\
|
|
|
+=\sum_{i=1}^m[y_i(\hat\alpha_i-\alpha_i)-\epsilon(\hat\alpha_i+\alpha_i)]+\sum_{i=1}^m(\alpha_i\hat\varepsilon_i-\mu_i\hat\varepsilon_i-\hat\mu_i\hat\varepsilon_i-\hat\alpha_i\hat\varepsilon_i)-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m(\hat\alpha_i-\alpha_i)(\hat|alpha_j-\alpha_j)x_i^Tx_j\\
|
|
|
+=\sum_{i=1}^m[y_i(\hat\alpha_i-\alpha_i)-\epsilon(\hat\alpha_i+\alpha_i)]+\sum_{i=1}^m[(\alpha_i+\mu_i)-(\hat\mu_i+\hat\alpha_i)]\hat\varepsilon_i-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m(\hat\alpha_i-\alpha_i)(\hat|alpha_j-\alpha_j)x_i^Tx_j\\
|
|
|
+=\sum_{i=1}^m[y_i(\hat\alpha_i-\alpha_i)-\epsilon(\hat\alpha_i+\alpha_i)]-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m(\hat\alpha_i-\alpha_i)(\hat|alpha_j-\alpha_j)x_i^Tx_j
|
|
|
+\end{aligned}$$ $$\tag{6.51}\sum_{i=1}^m[y_i(\hat\alpha_i-\alpha_i)-\epsilon(\hat\alpha_i+\alpha_i)]-\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m(\hat\alpha_i-\alpha_i)(\hat|alpha_j-\alpha_j)x_i^Tx_j$$ $$s.t.\sum_{i=1}^m(\hat\alpha_i-\alpha_i)=0$$ $$0\leq\alpha_i,\hat\alpha_i\leq C$$
|
|
|
+
|
|
|
+上述过程满足KKT条件,即要求
|
|
|
+$$\tag{6.52}\begin{cases}\\
|
|
|
+\alpha_i(f(x_i)-y_i-\epsilon-\varepsilon_i)=0 \\
|
|
|
+\hat\alpha_i(y_i-f(x_i)-\epsilon-\varepsilon_i)=0\\
|
|
|
+\alpha_i\hat\alpha_i=0,\varepsilon_i\hat\varepsilon_i=0\\
|
|
|
+(C-\alpha_i)\varepsilon_i=0,(c-\hat\alpha_i)\hat\varepsilon_i=0
|
|
|
+\end{cases}r
|
|
|
+$$
|
|
|
+
|
|
|
+
|
|
|
+将式6.47代入6.7
|
|
|
+$$\tag{6.7} f(x) = w^Tx+b$$ $$\tag{6.47}w=\sum_{i=1}^m(\hat\alpha_i-\alpha_i)x_i $$ $$\tag{6.53}f(x)=\sum_{i=1}^m(\hat\alpha_i-\alpha_i)x_i^Tx+b$$
|
|
|
+
|
|
|
+
|
|
|
+$$\tag{6.54}b=y_i+\epsilon-\sum_{j=1}^m(\hat\alpha_j\alpha_j)x_j^Tx_i$$
|
|
|
+
|
|
|
+$$\tag{6.55}w=\sum_{i=1}^m(\hat\alpha_i-\alpha_i)\phi (x_i)$$
|
|
|
+
|
|
|
+
|
|
|
+$$\tag{6.56}f(x)=\sum_{i=1}^m(\hat\alpha_i-\alpha_i)k(x,x_i)+b$$ $$其中k(x_i,x_j)=\phi(x_i)^T \phi(x_j)为核函数$$
|
|
|
+
|
|
|
+## 6.6 核方法[公式6.57-6.70]
|
|
|
+它的核心思想是将数据映射到高维空间中,希望在高维空间中数据具有更好的区分性,而核函数是用来计算映射到高维空间中内积的一种方法,也就是说核方法的本质应该是内积,而内积又恰恰定义了相似度。
|
|
|
+
|
|
|
+[再生核希尔伯特空间](https://blog.csdn.net/haolexiao/article/details/72171523?utm_source=itdadao&utm_medium=referral)
|
|
|
+$$\tag{6.57} \underbrace{min}_{\text{$h \in H$}}F(h) = \varOmega(||h||_H)+\ell(h(x_1),h(x_2)\dots h(x_m))$$
|
|
|
+
|
|
|
+$$\tag{6.58} h^*(x) = \sum_{i=1}^m\alpha_i\kappa(x,x_i)$$
|
|
|
+[证明见wiki](https://en.wikipedia.org/wiki/Representer_theorem)
|
|
|
+
|
|
|
+将样本映射到高维空间,进行线性判别分析
|
|
|
+$$\tag{6.59} h(x) =w^T\text{\o}(x)$$
|
|
|
+
|
|
|
+
|
|
|
+$$\tag{6.60} \underbrace{max}_{\text{$w$}}J(w) = \frac{w^TS_b^{\text{\o}}w}{w^TS_w^{\text{\o}}w}$$
|
|
|
+
|
|
|
+$$\tag{6.61} \mu_i^{\text{\o}} = \frac{1}{m_i}\sum_{x\in X_i}\text{\o}(x)$$
|
|
|
+
|
|
|
+$$\tag{6.62} S_b^{\text{\o}}=(\mu_1^{\text{\o}}- \mu_0^{\text{\o}})(\mu_1^{\text{\o}}- \mu_0^{\text{\o}})^T$$
|
|
|
+
|
|
|
+$$\tag{6.63} S_w^{\text{\o}}=\sum_{i=0}^{1}\sum_{x\in X_i}({\text{\o}}(x)- \mu_i^{\text{\o}})({\text{\o}}(x)- \mu_i^{\text{\o}})^T$$
|
|
|
+
|
|
|
+$$\tag{6.64} h(x) = \sum_{i=1}^m\alpha_i\kappa(x,x_i) = \sum_{i=1}^m\alpha_i{\text{\o}}(x)^T{\text{\o}}(x_i) =w^T\text{\o}(x)$$
|
|
|
+
|
|
|
+
|
|
|
+$$\tag{6.65} w = \sum_{i=1}^m\alpha_i{\text{\o}}(x_i)$$
|
|
|
+**推导6.65**
|
|
|
+$$ h(x) = \sum_{i=1}^m\alpha_i{\text{\o}}(x)^T{\text{\o}}(x_i) =w^T\text{\o}(x)$$
|
|
|
+
|
|
|
+$$\tag{6.66} \hat{\mu}_0 =\frac{1}{m_0}Kl_0$$
|
|
|
+
|
|
|
+$$\tag{6.67} \hat{\mu}_0 =\frac{1}{m_1}Kl_1$$
|
|
|
+
|
|
|
+$$\tag{6.68} M=(\hat{\mu}_0-\hat{\mu}_1)(\hat{\mu}_0-\hat{\mu}_1)^T = S_b^{\text{\o}}$$
|
|
|
+
|
|
|
+$$ \tag{6.69} N = KK^T-\sum_{i=0}^1m_i\hat{\mu}_i\hat{\mu}_i^T = S_w^{\text{\o}} $$
|
|
|
+
|
|
|
+$$ \tag{6.70} \underbrace{max}_{\text{$w$}}J(\alpha)= \frac{\alpha^TM\alpha}{\alpha^TN\alpha}$$
|
|
|
+
|

 heitao
heitao