## 2.20
$$\text{AUC}=\frac{1}{2}\sum_{i=1}^{m-1}(x_{i+1} - x_i)\cdot(y_i + y_{i+1})$$
[解析]:在解释$\text{AUC}$公式之前,我们需要先弄清楚$\text{ROC}$曲线的具体绘制过程,下面我们就举个例子,按照西瓜书图2.4下方给出的绘制方法来讲解一下$\text{ROC}$曲线的具体绘制过程。假设我们已经训练得到一个学习器$f(s)$,现在用该学习器来对我们的8个测试样本(4个正例,4个反例,也即$m^+=m^-=4$)进行预测,假设预测结果为:
$$(s_1,0.77,+),(s_2,0.62,-),(s_3,0.58,+),(s_4,0.47,+),(s_5,0.47,-),(s_6,0.33,-),(s_7,0.23,+),(s_8,0.15,-)$$
其中,$+$和$-$分别表示为正例和为反例,里面的数字表示学习器$f(s)$预测该样本为正例的概率,例如对于反例$s_2$来说,当前学习器$f(s)$预测它是正例的概率为$0.62$。根据西瓜书上给出的绘制方法可知,首先需要对所有测试样本按照学习器给出的预测结果进行排序(上面给出的预测结果已经按照预测值从大到小排好),接着将分类阈值设为一个不可能取到的最大值,显然这时候所有样本预测为正例的概率都一定小于分类阈值,那么预测为正例的样本个数为0,相应的真正例率和假正例率也都为0,所以此时我们可以在坐标$(0,0)$处打一个点。接下来我们需要把分类阈值从大到小依次设为每个样本的预测值,也就是依次设为$0.77、0.62、0.58、0.47、0.33、0.23、0.15$,然后每次计算真正例率和假正例率,再在相应的坐标上打一个点,最后再将各个点用直线串连起来即可得到$\text{ROC}$曲线。需要注意的是,在统计预测结果时,预测值等于分类阈值的样本也算作预测为正例。例如,当分类阈值为$0.77$时,测试样本$s_1$被预测为正例,由于它的真实标记也是正例,所以此时$s_1$是一个真正例。为了便于绘图,我们将$x$轴(假正例率轴)的“步长”定为$\frac{1}{m^-}$,$y$轴(真正例率轴)的“步长”定为$\frac{1}{m^+}$,这样的话,根据真正例率和假正例率的定义可知,每次变动分类阈值时,若新增$i$个假正例,那么相应的$x$轴坐标也就增加$\frac{i}{m^-}$,同理,若新增$j$个真正例,那么相应的$y$轴坐标也就增加$\frac{j}{m^+}$。按照以上讲述的绘制流程,最终我们可以绘制出如下图所示的$\text{ROC}$曲线
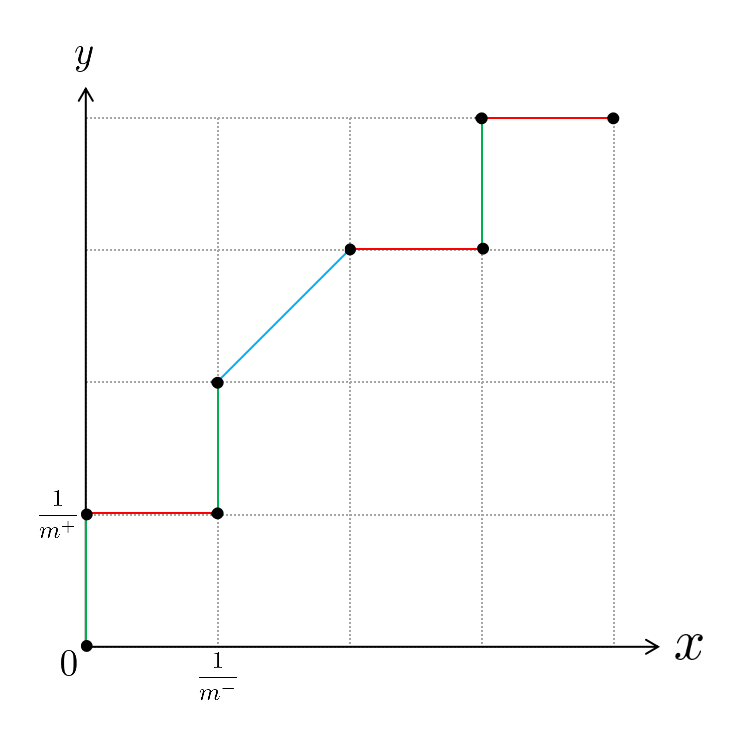 在这里我们为了能在解析公式(2.21)时复用此图所以没有写上具体地数值,转而用其数学符号代替。其中绿色线段表示在分类阈值变动的过程中只新增了真正例,红色线段表示只新增了假正例,蓝色线段表示既新增了真正例也新增了假正例。根据$\text{AUC}$值的定义可知,此时的$\text{AUC}$值其实就是所有红色线段和蓝色线段与$x$轴围成的面积之和。观察上图可知,红色线段与$x$轴围成的图形恒为矩形,蓝色线段与$x$轴围成的图形恒为梯形,但是由于梯形面积公式既能算梯形面积,也能算矩形面积,所以无论是红色线段还是蓝色线段,其与$x$轴围成的面积都能用梯形公式来计算,也即
$$\frac{1}{2}\cdot(x_{i+1} - x_i)\cdot(y_i + y_{i+1})$$
其中,$(x_{i+1} - x_i)$表示“高”,$y_i$表示“上底”,$y_{i+1}$表示“下底”。那么
$$\sum_{i=1}^{m-1}\left[\frac{1}{2}\cdot(x_{i+1} - x_i)\cdot(y_i + y_{i+1})\right]$$
表示的便是对所有红色线段和蓝色线段与$x$轴围成的面积进行求和,此即为$\text{AUC}$
## 2.21
$$\ell_{rank}=\frac{1}{m^+m^-}\sum_{\boldsymbol{x}^+ \in D^+}\sum_{\boldsymbol{x}^- \in D^-}\left(\mathbb{I}\left(f(\boldsymbol{x}^+)[1]
设某事件发生的概率为$p$,$p$未知,作$m$次独立试验,每次观察该事件是否发生,以$X$记该事件发生的次数,则$X$服从二项分布$B(m,p)$,现根据$X$检验如下假设:
$$\begin{aligned}
H_0:p\leq p_0\\
H_1:p > p_0
\end{aligned}$$
由二项分布本身的特性可知:$p$越小,$X$取到较小值的概率越大。因此,对于上述假设,一个直观上合理的检验为
$$\varphi:\text{当}X\leq C\text{时接受}H_0,\text{否则就拒绝}H_0$$
其中,$C\in N$表示事件最大发生次数。此检验对应的功效函数为
$$\begin{aligned}
\beta_{\varphi}(p)&=P(X>C)\\
&=1-P(X\leq C) \\
&=1-\sum_{i=0}^{C}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p^{i} (1-p)^{m-i} \\
&=\sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p^{i} (1-p)^{m-i} \\
\end{aligned}$$
由于“$p$越小,$X$取到较小值的概率越大”可以等价表示为:$P(X\leq C)$是关于$p$的减函数(更为严格的数学证明参见参考文献[1]中第二章习题7),所以$\beta_{\varphi}(p)=P(X>C)=1-P(X\leq C)$是关于$p$的增函数,那么当$p\leq p_0$时,$\beta_{\varphi}(p_0)$即为$\beta_{\varphi}(p)$的上确界。又因为,根据参考文献[1]中5.1.3的定义1.2可知,检验水平$\alpha$默认取最小可能的水平,所以在给定检验水平$\alpha$时,可以通过如下方程解得满足检验水平$\alpha$的整数$C$:
$$\alpha =\sup \left\{\beta_{\varphi}(p)\right\}$$
显然,当$p\leq p_0$时:
$$\begin{aligned}
\alpha &=\sup \left\{\beta_{\varphi}(p)\right\} \\
&=\beta_{\varphi}(p_0) \\
&=\sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i}
\end{aligned}$$
对于此方程,通常不一定正好解得一个整数$C$使得方程成立,较常见的情况是存在这样一个$\overline{C}$使得
$$\sum_{i=\overline{C}+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i}<\alpha \\
\sum_{i=\overline{C}}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i}>\alpha$$
此时,$C$只能取$\overline{C}$或者$\overline{C}+1$,若$C$取$\overline{C}$,则相当于升高了检验水平$\alpha$,若$C$取$\overline{C}+1$则相当于降低了检验水平$\alpha$,具体如何取舍需要结合实际情况,但是通常为了减小犯第一类错误的概率,会倾向于令$C$取$\overline{C}+1$。下面考虑如何求解$\overline{C}$:易证$\beta_{\varphi}(p_0)$是关于$C$的减函数,所以再结合上述关于$\overline{C}$的两个不等式易推得
$$\overline{C}=\min C\quad\text { s.t. } \sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i}(1-p_0)^{m-i}<\alpha$$
## 参考文献
[1]陈希孺编著.概率论与数理统计[M].中国科学技术大学出版社,2009.
在这里我们为了能在解析公式(2.21)时复用此图所以没有写上具体地数值,转而用其数学符号代替。其中绿色线段表示在分类阈值变动的过程中只新增了真正例,红色线段表示只新增了假正例,蓝色线段表示既新增了真正例也新增了假正例。根据$\text{AUC}$值的定义可知,此时的$\text{AUC}$值其实就是所有红色线段和蓝色线段与$x$轴围成的面积之和。观察上图可知,红色线段与$x$轴围成的图形恒为矩形,蓝色线段与$x$轴围成的图形恒为梯形,但是由于梯形面积公式既能算梯形面积,也能算矩形面积,所以无论是红色线段还是蓝色线段,其与$x$轴围成的面积都能用梯形公式来计算,也即
$$\frac{1}{2}\cdot(x_{i+1} - x_i)\cdot(y_i + y_{i+1})$$
其中,$(x_{i+1} - x_i)$表示“高”,$y_i$表示“上底”,$y_{i+1}$表示“下底”。那么
$$\sum_{i=1}^{m-1}\left[\frac{1}{2}\cdot(x_{i+1} - x_i)\cdot(y_i + y_{i+1})\right]$$
表示的便是对所有红色线段和蓝色线段与$x$轴围成的面积进行求和,此即为$\text{AUC}$
## 2.21
$$\ell_{rank}=\frac{1}{m^+m^-}\sum_{\boldsymbol{x}^+ \in D^+}\sum_{\boldsymbol{x}^- \in D^-}\left(\mathbb{I}\left(f(\boldsymbol{x}^+)[1]
设某事件发生的概率为$p$,$p$未知,作$m$次独立试验,每次观察该事件是否发生,以$X$记该事件发生的次数,则$X$服从二项分布$B(m,p)$,现根据$X$检验如下假设:
$$\begin{aligned}
H_0:p\leq p_0\\
H_1:p > p_0
\end{aligned}$$
由二项分布本身的特性可知:$p$越小,$X$取到较小值的概率越大。因此,对于上述假设,一个直观上合理的检验为
$$\varphi:\text{当}X\leq C\text{时接受}H_0,\text{否则就拒绝}H_0$$
其中,$C\in N$表示事件最大发生次数。此检验对应的功效函数为
$$\begin{aligned}
\beta_{\varphi}(p)&=P(X>C)\\
&=1-P(X\leq C) \\
&=1-\sum_{i=0}^{C}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p^{i} (1-p)^{m-i} \\
&=\sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p^{i} (1-p)^{m-i} \\
\end{aligned}$$
由于“$p$越小,$X$取到较小值的概率越大”可以等价表示为:$P(X\leq C)$是关于$p$的减函数(更为严格的数学证明参见参考文献[1]中第二章习题7),所以$\beta_{\varphi}(p)=P(X>C)=1-P(X\leq C)$是关于$p$的增函数,那么当$p\leq p_0$时,$\beta_{\varphi}(p_0)$即为$\beta_{\varphi}(p)$的上确界。又因为,根据参考文献[1]中5.1.3的定义1.2可知,检验水平$\alpha$默认取最小可能的水平,所以在给定检验水平$\alpha$时,可以通过如下方程解得满足检验水平$\alpha$的整数$C$:
$$\alpha =\sup \left\{\beta_{\varphi}(p)\right\}$$
显然,当$p\leq p_0$时:
$$\begin{aligned}
\alpha &=\sup \left\{\beta_{\varphi}(p)\right\} \\
&=\beta_{\varphi}(p_0) \\
&=\sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i}
\end{aligned}$$
对于此方程,通常不一定正好解得一个整数$C$使得方程成立,较常见的情况是存在这样一个$\overline{C}$使得
$$\sum_{i=\overline{C}+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i}<\alpha \\
\sum_{i=\overline{C}}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i}>\alpha$$
此时,$C$只能取$\overline{C}$或者$\overline{C}+1$,若$C$取$\overline{C}$,则相当于升高了检验水平$\alpha$,若$C$取$\overline{C}+1$则相当于降低了检验水平$\alpha$,具体如何取舍需要结合实际情况,但是通常为了减小犯第一类错误的概率,会倾向于令$C$取$\overline{C}+1$。下面考虑如何求解$\overline{C}$:易证$\beta_{\varphi}(p_0)$是关于$C$的减函数,所以再结合上述关于$\overline{C}$的两个不等式易推得
$$\overline{C}=\min C\quad\text { s.t. } \sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i}(1-p_0)^{m-i}<\alpha$$
## 参考文献
[1]陈希孺编著.概率论与数理统计[M].中国科学技术大学出版社,2009.