
chapter2_FR.md 20 KB
2.20
$$\text{AUC}=\frac{1}{2}\sum{i=1}^{m-1}(x{i+1} - x_i)\cdot(yi + y{i+1})$$
[Analyse]:Avant d'expliquer la formule $\text{AUC}$, Nous devons d'abord comprendre le processus pour dessiner la courbe $\text{ROC}$. On expliquera la processus pour dessiner la courbe $\text{ROC}$ selon la méthode de dessin donnée en bas de la figure 2.4 du Watermelon-Book. Supposons que nous ayons formé un apprenant $f(s)$, on ttilise maintenant cette apprenant pour tester nos 8 échantillons de test (4 cas positive et 4 negative, donc $m^+=m^-=4$) afin de procéder la prodiction, supposons le résultat de la prédiction est
$$(s_1,0.77,+),(s_2,0.62,-),(s_3,0.58,+),(s_4,0.47,+),(s_5,0.47,-),(s_6,0.33,-),(s_7,0.23,+),(s_8,0.15,-)$$
dedans, $+$和$-$ représente respectivement comme exemples positifs et exemples négatifs, le numéro dedans signifie la probabilité de l'échantillion étant positive dans l'apprenant $f(s)$. Par exemple, pour le contre-exemple $s_2$, l'apprenant actuel $f(s)$ prédit que la probabilité qu'il s'agisse d'un exemple positif est de 0,62$. Selon la méthode de dessin indiquée dans le livre Watermelon, tous les échantillons de test doivent être triés en fonction des résultats de prédiction donnés par l'apprenant dans un premier temps (Le résultats dessus sont triés de grande valeur à petite). Ensuite, on règle le seuil de classification à une valeur maximale impossible à obtenir. Il est évidemment, à ce stade, la probabilité que tous les échantillons soient positifs doit être inférieure au seuil de classification, et le nombre d’échantillons prédits positifs est de 0. Les probabilités correspondants de vrais et de faux positifs sont également de 0, donc à ce stade, nous pouvons atteindre un point aux coordonnées $(0,0)$. Ensuite, nous devons définir le seuil de classification à la valeur prédite pour chaque échantillon, c’est-à-dire le définir à son tour $0.77、0.62、0.58、0.47、0.33、0.23、0.15$. Ensuite, chaque fois que les probabilités de vrais et de faux positifs sont calculés, un point est dessiné sur les coordonnées correspondantes. Enfin, on peut obtenir le $\text{ROC}$ curve en enchaînant les points en ligne droite. Il est à noter que lorsque des prévisions statistiques sont faites, les échantillons dont les valeurs de prévision sont égales aux seuils de classification sont également comptés comme des prédictions positives. Par exemple, le seuil de classification est égale à $0.77$, l'échantillon $s_1$ est prédit étant une prédiction positive. Parce que son vrai marque est aussi un exemple positif, $s1$ est un vrai exemple positif. Pour faciliter le dessin, on défine le pas de l'axe de $x$(l'axe de taux de faux positif) est égale à $\frac{1}{m^-}$, le pas de l'axe $y$ (l'axe de taux positif réel) est égale à $\frac{1}{m^+}$. Dans ce cas, Selon la définition des taux de vrais (TPR) et de faux positifs (FPR), Chaque fois que l'on modifie le seuil de classification, si on ajoute $i$ des faux positif, les coordonnées de l'axe $x$ augement $\frac{i}{m^-}$. De la même façon, si $j$ vrai positif est ajouté, les coordonnées de l'axe $y$ augement également $\frac{j}{m^+}$. Suivez le processus de dessin décrit ci-dessus, finalement, nous pouvons dessiner le diagramme suivant $\text{ROC}$
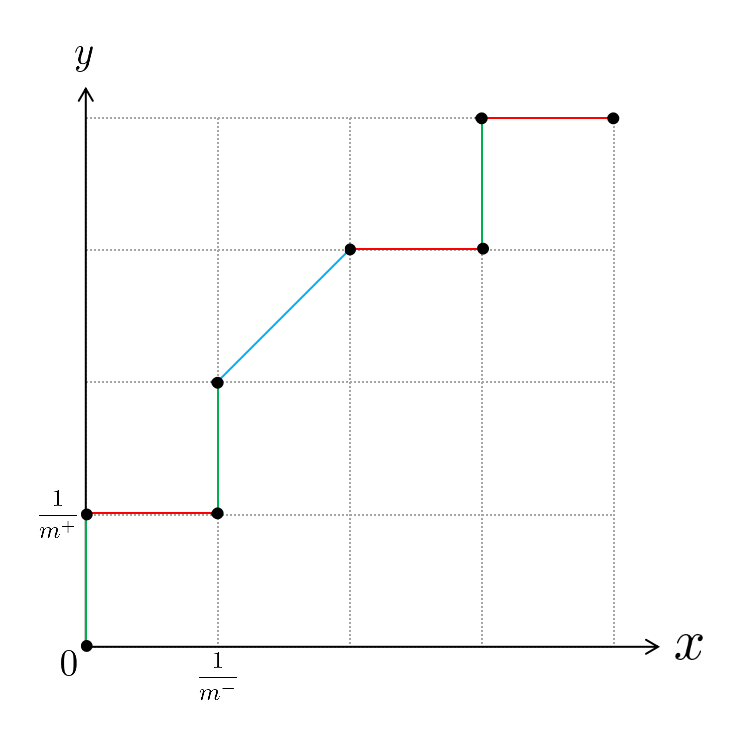 Ici, nous n’écrivons pas de valeurs spécifiques afin de pouvoir réutiliser ce graphique lors de l’analyse des formules (2.21), et le remplacer par ses symboles mathématiques. Lorsque le segment vert indique que seul l’exemple réel a été ajouté dans le processus de classification des changements de seuil, le segment rouge indique que seul l’exemple de faux positif a été ajouté et le segment bleu indique que le cas réel et l’exemple de faux positif ont été ajoutés. Selon la définition de $\text{AUC}$, la valeur de $\text{AUC}$ est en fait la somme de toutes les zones entourées de segments rouges et bleus et de l’axe $x$. Comme vous pouvez le voir sur l’image ci-dessus, le graphique entouré du segment rouge et de l’axe $x$ est rectangulaire, et les graphiques entourés du segment bleu et de l’axe $x$ sont rectangulaires. Cependant, étant donné que la formule de l’aire trapézoïdale peut compter à la fois l’aire trapézoïdale et la zone rectangulaire, la zone entourée de l’axe $x$ peut être calculée en utilisant à la fois les segments rouge et bleu, c’est-à-dire la formule
Ici, nous n’écrivons pas de valeurs spécifiques afin de pouvoir réutiliser ce graphique lors de l’analyse des formules (2.21), et le remplacer par ses symboles mathématiques. Lorsque le segment vert indique que seul l’exemple réel a été ajouté dans le processus de classification des changements de seuil, le segment rouge indique que seul l’exemple de faux positif a été ajouté et le segment bleu indique que le cas réel et l’exemple de faux positif ont été ajoutés. Selon la définition de $\text{AUC}$, la valeur de $\text{AUC}$ est en fait la somme de toutes les zones entourées de segments rouges et bleus et de l’axe $x$. Comme vous pouvez le voir sur l’image ci-dessus, le graphique entouré du segment rouge et de l’axe $x$ est rectangulaire, et les graphiques entourés du segment bleu et de l’axe $x$ sont rectangulaires. Cependant, étant donné que la formule de l’aire trapézoïdale peut compter à la fois l’aire trapézoïdale et la zone rectangulaire, la zone entourée de l’axe $x$ peut être calculée en utilisant à la fois les segments rouge et bleu, c’est-à-dire la formule
$$\frac{1}{2}\cdot(x{i+1} - x_i)\cdot(yi + y{i+1})$$
Il se trouve que $(x_{i+1} - x_i)$ dénote la hauteur, $yi$ est l'échelle haut, et $y{i+1}$ est l'échelle de bas. Dans ce cas,
$$\sum{i=1}^{m-1}\left[\frac{1}{2}\cdot(x{i+1} - x_i)\cdot(yi + y{i+1})\right]$$
Cela représente une somme des zones entourant tous les segments rouges et bleus et l’axe $x$, c'est à dire $\text{AUC}$
2.21
$$\ell{rank}=\frac{1}{m^+m^-}\sum{\boldsymbol{x}^+ \in D^+}\sum{\boldsymbol{x}^- \in D^-}\left(\mathbb{I}\left(f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)\right)+\frac{1}{2}\mathbb{I}\left(f(\boldsymbol{x}^+)=f(\boldsymbol{x}^-)\right)\right)$$ [Analyse]:Selon notre analyse de la formule ci-dessus (2.20), $\ell{rank}$ peut être considéré comme la somme de tous les segments verts et bleus et de la zone entourant l’axe $y$, Mais selon la formule (2.21), il est difficile à voir en un coup d’œil l'aire de cette zone, nous devons donc constamment déformer la formule (2.21). $$\begin{aligned} \ell{rank}&=\frac{1}{m^+m^-}\sum{\boldsymbol{x}^+ \in D^+}\sum{\boldsymbol{x}^- \in D^-}\left(\mathbb{I}\left(f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)\right)+\frac{1}{2}\mathbb{I}\left(f(\boldsymbol{x}^+)=f(\boldsymbol{x}^-)\right)\right) \ &=\frac{1}{m^+m^-}\sum{\boldsymbol{x}^+ \in D^+}\left[\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)\right)+\frac{1}{2}\cdot\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)=f(\boldsymbol{x}^-)\right)\right] \ &=\sum{\boldsymbol{x}^+ \in D^+}\left[\frac{1}{m^+}\cdot\frac{1}{m^-}\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)\right)+\frac{1}{2}\cdot\frac{1}{m^+}\cdot\frac{1}{m^-}\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)=f(\boldsymbol{x}^-)\right)\right] \ &=\sum{\boldsymbol{x}^+ \in D^+}\frac{1}{2}\cdot\frac{1}{m^+}\cdot\left[\frac{2}{m^-}\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)\right)+\frac{1}{m^-}\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)=f(\boldsymbol{x}^-)\right)\right] \ \end{aligned}$$ Selon la graph de $\text{ROC}$ donné par la formule (2.20), s’il y a de nouveaux exemples réels dans le processus de modification des seuils de classification, un segment vert ou bleu est ajouté en conséquence. Donc dans la formule ci-dessus $\sum\limits{\boldsymbol{x}^+ \in D^+}$ peut être considéré traversant tous les segments verts et bleus, les $\sum\limits{\boldsymbol{x}^+ \in D^+}$ correspondant, ce dernier élément est la zone autour de l’axe $y$ du segment vert ou du segment bleu, c’est-à-dire $$\frac{1}{2}\cdot\frac{1}{m^+}\cdot\left[\frac{2}{m^-}\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)\right)+\frac{1}{m^-}\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)=f(\boldsymbol{x}^-)\right)\right]$$ Comme la solution de formule (2.20), la zone graphique entourant par l’axe $y$ peut être calculée à l’aide d’une formule trapézoïdale, peu import qu’il s’agisse d’un segment vert ou d’un segment bleu. La formule est donc toujours une aire trapézoïdale. Ici, $\frac{1}{m^+}$ est la hauteur, l'élément dans la parenthèse est « échelle haut plus celle du bas ». Dérivons respectivement le « échelle supérieur » (le fond le plus court) et le « bas ». Pendant la dessin du $\text{ROC}$, lorsque l'on ajoute un faut positif, un unité sera également ajouté aux coordonnées de l'axe $x$, Donc, pour « échelle supérieur», c’est-à-dire la distance entre l’extrémité inférieure du segment vert ou bleu et l’axe $y$, elle est égale à $\frac{1}{m^-}$ multiplie par la nombre de prédiction de faux positifs qui sont supérieur à $\boldsymbol{x^+}$ donc, $$\frac{1}{m^-}\sum\limits{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)\right)$$ Pour l'échelle du bas, il est égal à $\frac{1}{m^-}$ multiplier par le nombre de faux positifs dont la valeur prédite est supérieure ou égale à $\boldsymbol{x^+}$, dans notre cas, $$\frac{1}{m^-}\left(\sum{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)\right)+\sum_{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)=f(\boldsymbol{x}^-)\right)\right)$$
2.27
$$\overline{\epsilon}=\max \epsilon\quad \text { s.t. } \sum{i= \epsilon{0} \times m+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) \epsilon^{i}(1-\epsilon)^{m-i}<\alpha$$
[Analyse]:À compter de décembre 2018, la 30e édition de la première édition sera imprimée, la formule (2.27) devrait être révisée en tant qu’errat $$\overline{\epsilon}=\min \epsilon\quad\text { s.t. } \sum_{i=\epsilon\times m+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) \epsilon_0^{i}(1-\epsilon_0)^{m-i}<\alpha$$ Le processus de l'interprétation est le suivant: comme on peut le voir dans le contexte du livre de pastèque, Le test d’hypothèse pour $\epsilon\leq\epsilon_0$ est équivalent au test d’hypothèse pour $p\leq p0$ décrit à l’annexe (1), de sorte que le taux d’erreur maximal $\overline{\epsilon}$ est résolu dans le livre de pastèques est équivalent à la fréquence maximale $\frac{\overline{C}}{m}$ à laquelle un événement se produit à l’annexe (1). Comme on le voit dans l’annexe (1). $$\overline{C}=\min C\quad\text { s.t. } \sum{i=C+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) p_0^{i}(1-p0)^{m-i}<\alpha$$ Par conséquent, $$\frac{\overline{C}}{m}=\min \frac{C}{m}\quad\text { s.t. } \sum{i=C+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) p_0^{i}(1-p_0)^{m-i}<\alpha$$ On replace $\frac{\overline{C}}{m},\frac{C}{m},p_0$ par sa équivalence $\overline{\epsilon},\epsilon,\epsilon0$, on obtient $$\overline{\epsilon}=\min \epsilon\quad\text { s.t. } \sum{i=\epsilon\times m+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) \epsilon_0^{i}(1-\epsilon_0)^{m-i}<\alpha$$
2.41
$$\begin{aligned} E(f ; D)=& \mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-y{D}\right)^{2}\right] \ =& \mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})+\bar{f}(\boldsymbol{x})-y{D}\right)^{2}\right] \ =& \mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y{D}\right)^{2}\right] \ &+\mathbb{E}{D}\left[+2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y{D}\right)\right] \ =& \mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y{D}\right)^{2}\right] \ =& \mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y+y-y{D}\right)^{2}\right] \ =& \mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)^{2}\right]+\mathbb{E}{D}\left[\left(y-y{D}\right)^{2}\right]\ &+2 \mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)\left(y-y{D}\right)\right]\ =& \mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\left(\bar{f}(\boldsymbol{x})-y\right)^{2}+\mathbb{E}{D}\left[\left(y{D}-y\right)^{2}\right] \end{aligned}$$
[Analyse]:
- Etape 1 à 2:on soustrait un $\bar{f}(\boldsymbol{x})$, puis on ajoute un $\bar{f}(\boldsymbol{x})$, il appartient à une simple déformation constante;
- Etape 2 à 3:Tout d’abord, développez la formule entre les parenthèses $$\mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}+\left(\bar{f}(\boldsymbol{x})-y{D}\right)^{2}+2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y{D}\right)\right]$$ Ensuite, en fonction de la nature de l'attentes de l’opération: $\mathbb{E}[X+Y]=\mathbb{E}[X]+\mathbb{E}[Y]$, on transforme la formule ci-dessus à $$ \mathbb{E}{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y{D}\right)^{2}\right] +\mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y{D}\right)\right]$$
- Étape 3-4 : Utilisez à nouveau les propriétés de calcul de l'attente statistique pour développer le dernier élément de la formule obtenue à l’étape 3
$$\mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y{D}\right)\right] = \mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] - \mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot y_{D}\right]$$
- Le premier élément est obtenu après l’expansion de la formule $$\mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] = \mathbb{E}{D}\left[2f(\boldsymbol{x} ; D)\cdot\bar{f}(\boldsymbol{x})-2\bar{f}(\boldsymbol{x})\cdot\bar{f}(\boldsymbol{x})\right]$$ $\bar{f}(\boldsymbol{x})$ est une constante, on obtient selon les propriétés de calcul de l'attente statistique: $\mathbb{E}[AX+B]=A\mathbb{E}[X]+B$ (A et B sont toute constantes), obtenons $$\mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] = 2\bar{f}(\boldsymbol{x})\cdot\mathbb{E}{D}\left[f(\boldsymbol{x} ; D)\right]-2\bar{f}(\boldsymbol{x})\cdot\bar{f}(\boldsymbol{x})$$ Comme on peut le voir la formule (2.37): $\mathbb{E}{D}\left[f(\boldsymbol{x} ; D)\right]=\bar{f}(\boldsymbol{x})$, ainsi $$\mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] = 2\bar{f}(\boldsymbol{x})\cdot\bar{f}(\boldsymbol{x})-2\bar{f}(\boldsymbol{x})\cdot\bar{f}(\boldsymbol{x})=0$$
- On calcule ensuite la deuxième élément $$\mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot y{D}\right]=2\mathbb{E}{D}\left[f(\boldsymbol{x} ; D)\cdot y{D}\right]-2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}{D}\left[y{D}\right]$$ Comme le bruit n'a aucun relation avec $f$, ainsi $f(\boldsymbol{x} ; D)$ et $yD$ sont deux variables aléatoires distinctes, selon la propriété du calcul de l'attente statistique: $\mathbb{E}[XY]=\mathbb{E}[X]\mathbb{E}[Y]$ ($X$ et $Y$ sont deux variables aléatoires distinctes), on obtient, $$\begin{aligned} \mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot y{D}\right]&=2\mathbb{E}{D}\left[f(\boldsymbol{x} ; D)\cdot y{D}\right]-2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}{D}\left[y{D}\right] \ &=2\mathbb{E}{D}\left[f(\boldsymbol{x} ; D)\right]\cdot \mathbb{E}{D}\left[y{D}\right]-2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}{D}\left[y{D}\right] \ &=2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}{D}\left[y{D}\right]-2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}{D}\left[y{D}\right] \ &= 0 \end{aligned}$$ 所以 $$\begin{aligned} \mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y{D}\right)\right] &= \mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] - \mathbb{E}{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot y_{D}\right] \ &= 0+0 \ &=0 \end{aligned}$$
- Etape 3-4: Identique aux étapes 1 à 2, on diminus $y$ puis on ajoute $y$, étant une simple déformation constante;
- Etape 5-6: Identique aux étapes 2 à 3, on fait l'expansion de la dernière élement selon les propriétés de calcul de l'attente statistique;
- Etape 6-7:comme $\bar{f}(\boldsymbol{x})$ et $y$ sont constantes, selon les propriétés de calcul de l'attente statistique, la 2ème élément de l'étape 6 devient $$\mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)^{2}\right]=\left(\bar{f}(\boldsymbol{x})-y\right)^{2}$$ De même, le dernier élément de l’étape 6 peut être transformé en $$2\mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)\left(y-y{D}\right)\right]=2\left(\bar{f}(\boldsymbol{x})-y\right)\mathbb{E}{D}\left[\left(y-y{D}\right)\right]$$ Étant donné que l’attente de bruit est supposée nulle à ce stade, c’est $\mathbb{E}{D}\left[\left(y-y{D}\right)\right]=0$, donc $$2\mathbb{E}{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)\left(y-y_{D}\right)\right]=2\left(\bar{f}(\boldsymbol{x})-y\right)\cdot 0=0$$
Annexe
①Test de paramètres de la distribution binaire [1]
La probabilité de l'évenement est $p$, $p$ est inconnue, on lance $m$ tests distincts, on observe si l’événement s’est produit, le nombre de fois que l’événement se produit est enregistré à $X$, alor que $X$ obéit à la distribution binaire $B(m,p)$. Les hypothèses suivantes sont maintenant testées par rapport à $X$ : $$\begin{aligned} H_0:p\leq p_0\ H_1:p > p_0 \end{aligned}$$ Les caractéristiques de la distribution binaire montre que: plus le $p$ est élevé, plus la probabilité que le $X $ obtienne une valeur petite est grande.Cependant, pour les hypothèses ci-dessus, un test intuitivement raisonnable est: $$\varphi:\text{Quand}X\leq C\text{acceptons}H_0,\text{or, on refuse}H0$$ ici, $C\in N$ désigne le nombre maximals de l'évènement. La fonction de l'éfficacité correspondante pour ce test est $$\begin{aligned} \beta{\varphi}(p)&=P(X>C)\ &=1-P(X\leq C) \ &=1-\sum{i=0}^{C}\left(\begin{array}{c}{m} \ {i}\end{array}\right) p^{i} (1-p)^{m-i} \ &=\sum{i=C+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) p^{i} (1-p)^{m-i} \ \end{aligned}$$ Parce que « plus le $p$ est petit, plus la probabilité que $X$ obtienne une valeur plus petite » peut être exprimée de manière équivalente comme : $P(X\leq C)$ est une function décroissante de $p$.(Preuve mathématique plus rigoureuse, voir chapitre 2 Exercice 7 dans Références 1), donc $\beta_{\varphi}(p)=P(X>C)=1-P(X\leq C)$ est une function croissante de $p$, dans ce cas, $p\leq p0$,$\beta{\varphi}(p0)$ est la limites réelles de $\beta{\varphi}(p)$. En outre, selon la définition 1.2 de 5.1.3 dans Références [1],Le niveau de test de $\alpha$ est le niveau minimum possible par défaut. Donc, au niveau de test donné de $\alpha$, le niveau de test $\alpha$ peut être satisfait en résolvant l’équation suivante: $$\alpha =\sup \left{\beta_{\varphi}(p)\right}$$ Apparament, quand $p\leq p0$: $$\begin{aligned} \alpha &=\sup \left{\beta{\varphi}(p)\right} \ &=\beta_{\varphi}(p0) \ &=\sum{i=C+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) p_0^{i} (1-p0)^{m-i} \end{aligned}$$ Pour cette équation, il n’est généralement pas possible de résoudre un entier de $C$ pour rendre l’équation valide, un scénario plus courant est l’existence d’un tel $\overline{C}$ $$\begin{aligned} \sum{i=\overline{C}+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) p_0^{i} (1-p0)^{m-i}<\alpha \ \sum{i=\overline{C}}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) p_0^{i} (1-p0)^{m-i}>\alpha \end{aligned}$$ Dans ce cas, $C$ est n'égale qu'à $\overline{C}$ ou $\overline{C}+1$, si on défine $C$ comme $\overline{C}$, équivaut à augmenter le niveau de test $\alpha$,si $C$ serait $\overline{C}+1$; il est équivaut à dimunuer le niveau de test $\alpha$. Des compromis spécifiques doivent être combinés avec la situation réelle, mais on défine $C$ étant $\overline{C}+1$, généralement pour réduire la probabilité de faire le premier type d’erreur. Voici comment résoudre $\overline{C}$: il est facile à prouver $\beta{\varphi}(p0)$ est une function décroissant de $C$, Alors combinons les deux inégalités faciles qui précède à propos de $\overline{C}$, on obtiendrait $$\overline{C}=\min C\quad\text { s.t. } \sum{i=C+1}^{m}\left(\begin{array}{c}{m} \ {i}\end{array}\right) p_0^{i}(1-p_0)^{m-i}<\alpha$$
Référence
[1]陈希孺编著.概率论与数理统计[M].中国科学技术大学出版社,2009.